Forecasting from Experience
Economic forecasting is not a single activity. Official forecasting and forecasting for financial market participants, for example, are different exercises. No-one knows what is going to happen but an official forecast is not supposed to indulge in flights of fancy. It represents an informed consensus about prospects, given what is already known for sure - tendencies that are in the data or the foreseeable consequences of recent events that have not yet had an impact on the data. A good model is necessary and sometimes sufficient for this type of forecasting.
Authors
Economic forecasting is not a single activity. Official forecasting and forecasting for financial market participants, for example, are different exercises. No-one knows what is going to happen but an official forecast is not supposed to indulge in flights of fancy. It represents an informed consensus about prospects, given what is already known for sure – tendencies that are in the data or the foreseeable consequences of recent events that have not yet had an impact on the data. A good model is necessary and sometimes sufficient for this type of forecasting. Sometimes, of course, an event not yet reflected in data may be novel and not reflected in the model either. In that case you overwrite the variables most affected as best you can and let the model draw out other implications.
That is inadequate when forecasting for the financial sector, when clients are chiefly concerned about how macroeconomic developments will affect financial markets. Tendencies that are in the data are sure to be in the market price so an official-style forecast has little practical value beyond revealing how authorities might react. Here, you are really trying to do pure forecasting not intelligent extrapolation. The question now is: given what is going on and given the existing consensus, where are they most likely to be wrong and how wrong could they be?
The cheap trick then is to reflect that most model-based forecasts, whether from econometrically-estimated structural models or VAR type models, produce time series that look like moving averages of actual data; they tend to flatten the peaks and troughs. Some City economists try to trade on that by simple exaggeration. People think it’s going up? Say it’s going up twice as much as they think! This trick, of course, does not always work.
A more creative procedure is to work by historical or geographical analogy. Most situations resemble something that happened in the past or somewhere else. It is instructive then to ask how in detail does the current situation differ from the previous one it resembles? We know how that turned out; what effect do we suppose the detailed differences will have? That procedure enabled a fund I managed to anticipate the 2008 recession and get profitably short even without knowing how parlous the situation of the banks was. The savings and loan crisis of the late 1980s and the doubling of the oil price with the first Gulf war had been enough to put the U.S. into recession in the early 90s. In late 2007 the oil price had quadrupled over the previous couple of years and there was a much bigger housing market slump with associated stresses in train. How did the situations differ? Well the level of household indebtedness in 2007 was much higher than it had been in 1990. That meant surely that a recession was highly likely. Perhaps in an official forecast you could not say so because the data were not foreshadowing it. In fact the model-based Bank of England did not call it even six months later, when it was already happening. But any financial forecaster would have been in dereliction of duty not to be warning at least of the strong possibility in late 2007.
The banks’ plight turned a 2 per cent recession into a 6 per cent recession and one with long lived consequences. Once again you could have anticipated those consequences to some extent from looking at the Japanese experience. Richard Koo of Nomura Research Institute did exactly that. No model had the richness to tell him what he inferred by a careful comparison of Japanese experience and the post-recession situation in the West.
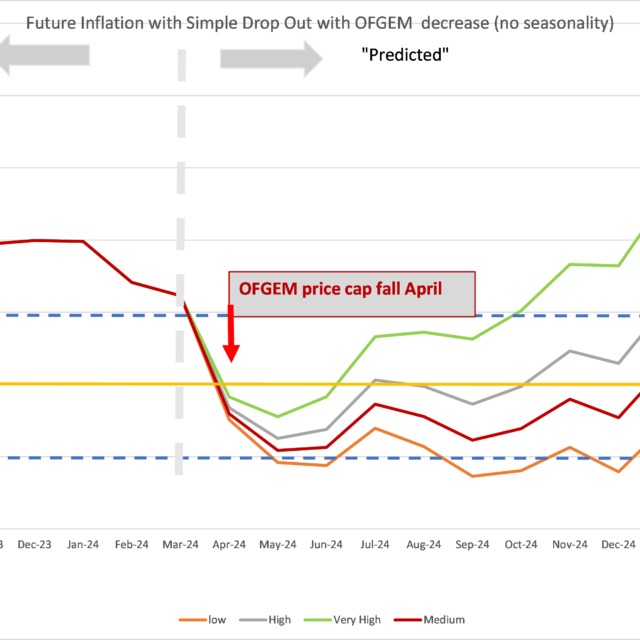
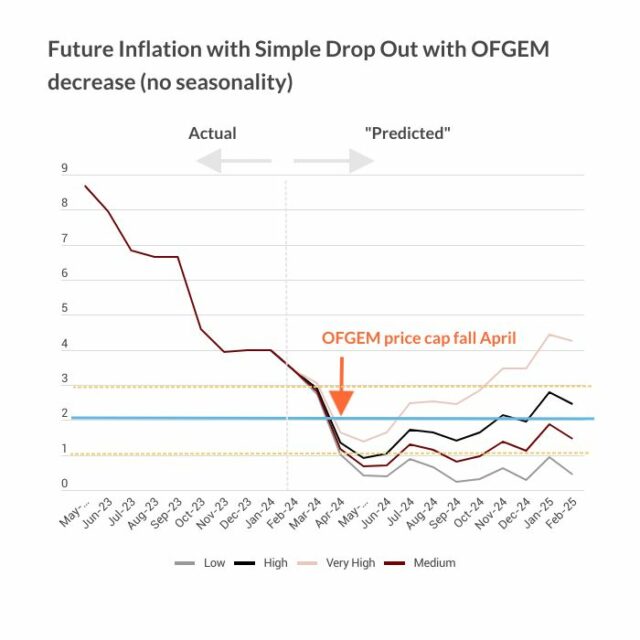
Just as economic forecasting differs with circumstances (and clients) so does the assessment of risk. It is now common with official forecasts to produce fan charts, showing the range of probable outcomes, based on the root mean squared error of past forecasts. The fallacy underlying this procedure is illustrated by the fact that during the last recession outcomes were well outside the range depicted in the fan charts of official forecasters like the Bank of England. The error here is to assume that forecast errors are drawn from a single probability distribution so we can calculate its moments and construct the fan. Yet the mean forecast error for GDP one year ahead is little bigger than half a per cent most of the time. When nothing much is happening, model-based extrapolation works pretty well. At big cyclical turning points like 1974, 1980 or 2007, at peaks and troughs, the error is closer to 4 per cent.
Now if you take a weighted average of the 4 per cent errors and the 1/2 per cent errors you decide that the standard deviation for the purposes of the fan is 2 per cent. But that is far too wide normally and too small if you are near a cyclical turning point so the fan chart is useless. There are two distributions not one. You have to make a prior decision whether you are in state one or state two and adjust the fan accordingly. How? I know of no sure method but paying attention to relevant history will help.
Gerald Holtham is Visiting Professor of Regional Economy, Cardiff Metropolitan University
Related Blog Posts


Related Projects


Related News


Why it’s not worth worrying that the UK has technically entered a recession
26 Feb 2024
4 min read
1.2 million UK Households Insolvent This Year as a Direct Result of Higher Mortgage Repayments
22 Jun 2023
2 min read
Related Publications

Recessionary Pressures Receding in the Rearview Mirror as UK Economy Gains Momentum
12 Apr 2024
GDP Trackers
Related events

Summer 2023 Economic Forum

Spring 2023 Economic Forum

Winter 2023 Economic Forum

Autumn 2022 Economic Forum
Summer 2022 Economic Forum

Spring 2022 Economic Forum

Winter 2022 Economic Forum
